YOLO 全域語意增強的演進
設計問題:全域語意如何建模
Residual、CSP 與 ELAN / GELAN 已逐步優化 Backbone 的核心問題:
- 深層網路的可訓練性
- 梯度重複與計算冗餘
- 梯度路徑分佈與資訊保留能力
這些設計讓模型能夠更深且穩定地學習,但在物體偵測任務中,仍存在另一個限制:全域語意建模能力不足。
局部感受野限制語意理解能力
卷積本質上是局部運算,即使透過多層堆疊擴大理論感受野,實際的**有效感受野(Effective Receptive Field)**仍集中於中心區域,導致:
- 大型物體的整體結構難以完整建模
- 密集場景中缺乏全域關係理解
- 複雜背景下的上下文語意不足
深層特徵的語意雖然更強,但其空間感知範圍仍然有限。
以深度換感受野的成本過高
若僅依賴增加卷積層數來擴展感受野,將帶來明顯代價:
- 網路深度持續增加
- 計算量與延遲上升
- 記憶體與推論成本提高
這與即時物體偵測對速度與效率的需求相衝突。
單純透過加深網路來獲取全域資訊,並不是可持續的設計策��略。
多尺度上下文建模
為了在不增加網路深度與計算成本的情況下提升全域語意能力,YOLO 在 Backbone 的高層特徵中引入 Spatial Pyramid Pooling(SPP),透過單一特徵層內的多尺度上下文建模,強化模型對不同尺寸物體與複雜場景的理解能力。
- 設計動機
- 深層特徵雖具備語意,但卷積的有效感受野仍有限
- 單一尺度特徵難以同時捕捉局部細節與大範圍上下文
- 核心機制
- 在 backbone 高層特徵上進行 多尺度 pooling
- 將不同感受野的特徵進行 concat
- 讓同一層特徵同時包含:
- 局部結構資訊
- 大範圍上下文語意
- 設計意義
- 在不增加網路深度的情況下提升全域感知能力
- 強化對大物體、密集場景與複雜背景的辨識穩定性
- 為後續 Neck 的多尺度融合提供更具上下文資訊的高層語意特徵
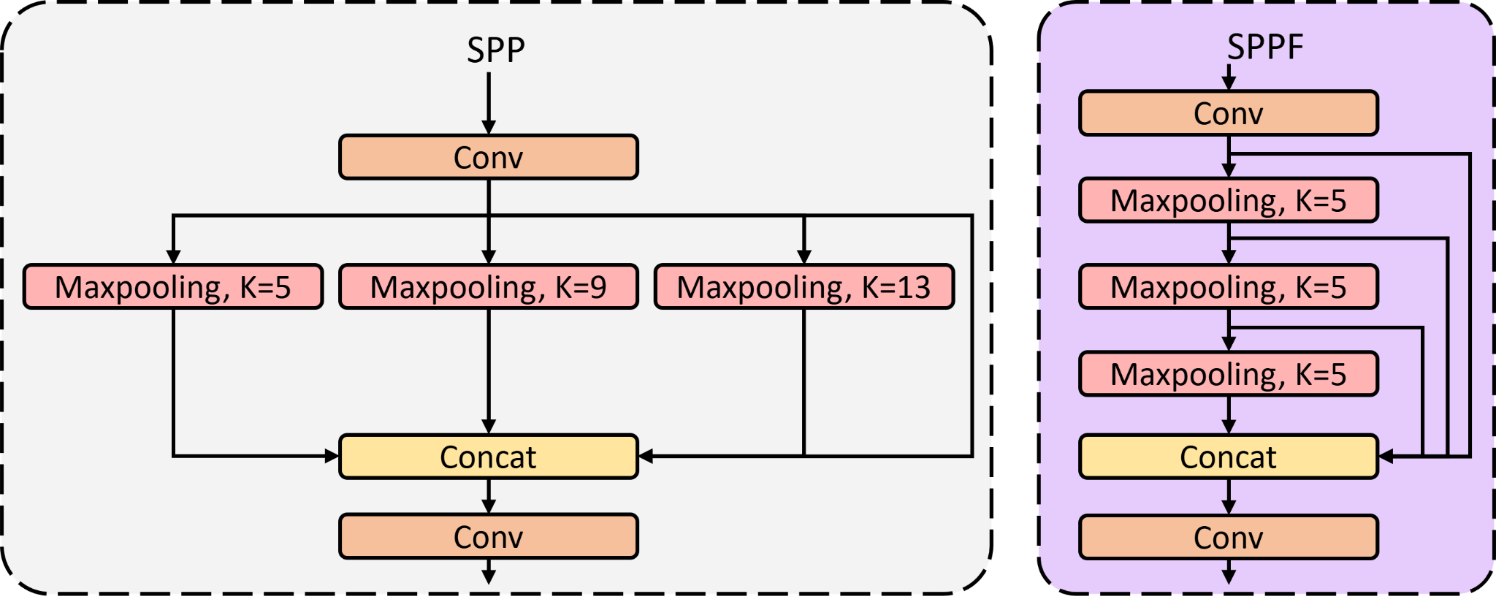
SPP:並行多尺度池化的上下文建模
- 設計概念
- 在同一特徵層上使用不同大小的 max pooling kernel
- 常見配置:5×5、9×9、13×13
- 核心機制
- 各��尺度 pooling 並行計算
- 將結果與原特徵 concat
- 建立不同感受野的特徵組合
- 設計效果
- 同時捕捉:
- 局部細節
- 中距離結構
- 全域上下文
- 提升對大物體與複雜場景的穩定性
- 同時捕捉:
- 影響
- 成為 YOLOv4 的上下文模組
問題
多個大尺寸 pooling 需並行計算,會增加 memory traffic 與推論延遲,成為即時模型中的效率瓶頸。
SPPF:序列式快速金字塔池化
- 設計動機
- SPP 的並行大核 pooling 帶來較高的延遲與記憶體開銷
- 核心機制
- 使用 連續的 5×5 max pooling
- 透過多次堆疊來模擬大感受野效果
- 最後將各階段輸出與原特徵 concat
- 設計優勢
- 計算量與記憶體存取顯著降低
- 推論速度更快
- 輸出效果與 SPP 幾乎相同
- 影響
- 成為 YOLOv5–YOLOv11 的��標準上下文模組
- 在保持即時性的前提下提供多尺度上下文能力
關鍵
SPP/SPPF 透過多尺度池化在不增加深度的情況下擴大感受野,為後續多尺度融合提供更完整的上下文資訊。
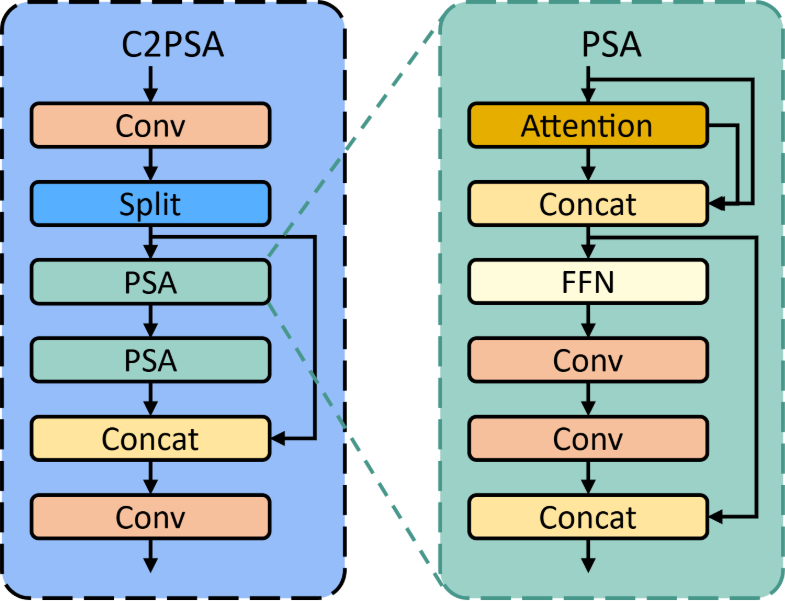
C2PSA:引入全域關係建模(YOLOv11)
相較於 SPP/SPPF 透過擴大感受野來補強上下文,C2PSA 直接在 CSP 結構中引入 Partial Self-Attention(PSA),使模型能學習長距離的跨區域特徵關係。
- 設計動機
- 卷積與 pooling 只能提供近似的全域感受野
- 缺乏對遠距離區域之間關聯建模的能力
- 需要在維持即時性的前提下,引入全域資訊互動
- 核心結構
- 基於 C2f/CSP 架構設計
- 將輸入通道分為兩部分:
- Partial channels:進行 Self-Attention 計算
- Remaining channels:維持卷積路徑
- 最後進行 concat 融合
- Partial Self-Attention 的意義
- 僅對部分特徵做 attention,避免:
- 計算量爆炸(O(N²))
- 記憶體成本過高
- 在保持 CNN 效率 的同時,引入 Transformer 式全域關係建模
- 僅對部分特徵做 attention,避免:
- 使用位置特性
- 主要用於 Backbone 深層(低解析度特徵)
- 因特徵尺寸較小,attention 成本可控
- 在部分模型配置中可選擇應用於 Neck
- 不改變 PAFPN 結構
- 設計意義
- 建立遠距離區域之間的語意關聯
- 改善:
- 大物體整體結構理解
- 密集場景關係建模
- 複雜背景下的判斷穩定性
- 讓 YOLO 從純 CNN 架構邁向 CNN + Attention 的混合設計
關鍵
C2PSA 在維持即時推論效率的前提下,引入可控成本的 Self-Attention,使 YOLO 首次具備顯式全域關係建模能力,代表其從局部卷積架構走向 Hybrid Vision 模型的重要演進。