機器學習任務攻略
基本任務流程
機器學習的過程通常包含以下階段:
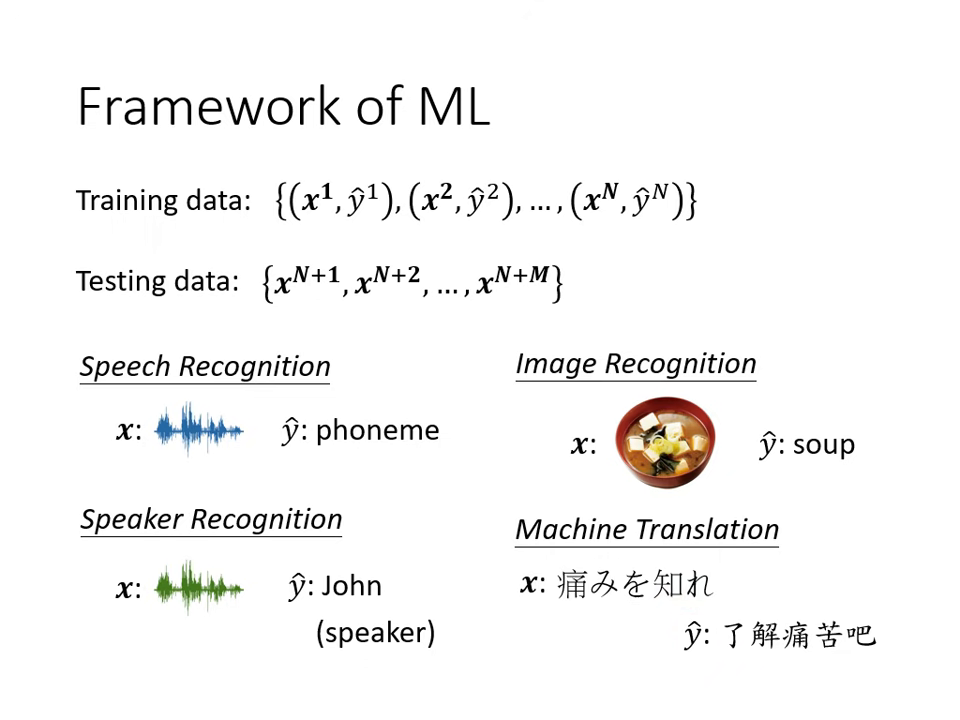
- 準備資料:訓練資料包含輸入 與標籤 ;測試資料則僅有 。
- 應用實例:語音辨識( 為訊號, 為音標)、影象辨識(辨識圖片內容)、語者辨識(判斷說話者身份)、機器翻譯。
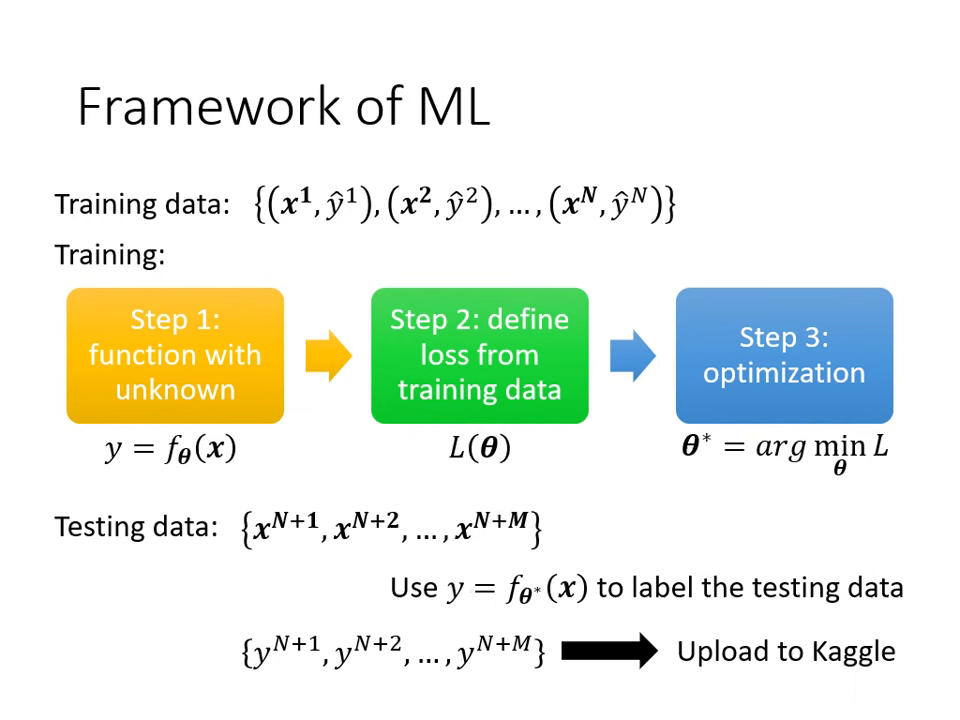
- 訓練模型(三個步驟):
- 定義一個含未知參數 的函數 。
- 定義損失函數 (Loss function),判斷參數好壞。
- 最佳化 (Optimization):找出能讓損失值最小的參數 。
 |  |
|---|---|
| 應用實例 | 訓練模型(三個步驟) |
核心攻略:如何診斷與解決問題
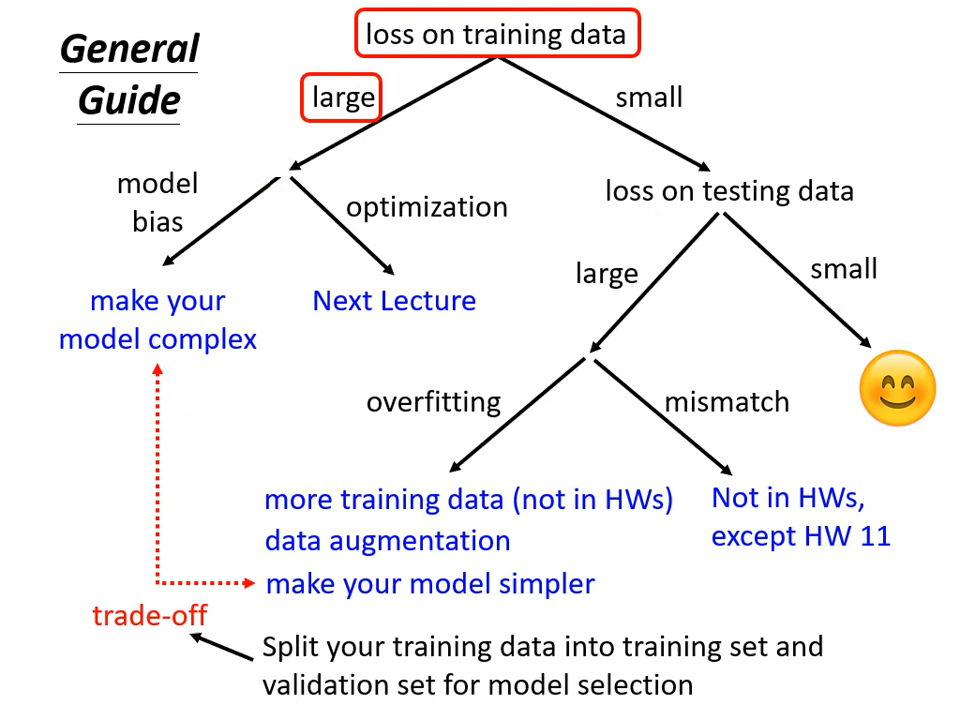
當模型在測試資料上的結果不滿意時,請依照下列流程檢查:
檢查訓練資料的損失 (Training Data Loss)
首先要確認模型在訓練集上是否已經學好,而非直接看測試集的結果。
-
狀況 A:訓練損失過大 (Training Loss is large)
- 原因 1:模型偏差 (Model Bias)
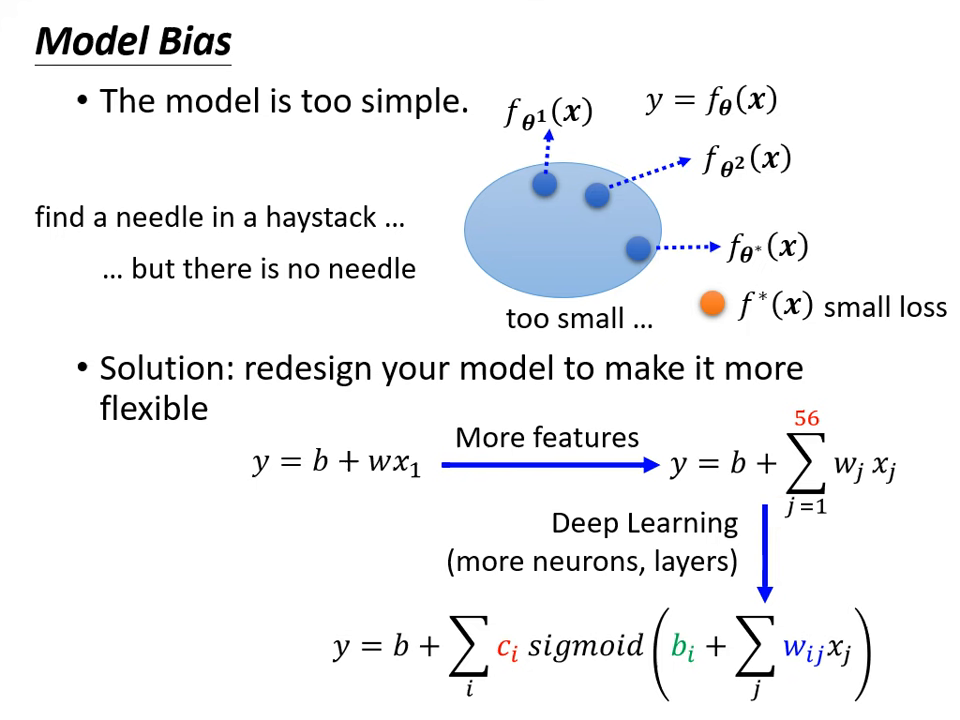
- 現象:模型過於簡單,其函數集合 (Function Set) 太小,根本不包含能讓損失變低的函數(如「大海撈針,針不在海裡」)。
- 對策:增加模型彈性。例如:增加輸入特徵 (Features)、增加模型深度或層數(Deep Learning)。
- 原因 2:最佳化問題 (Optimization Issue)
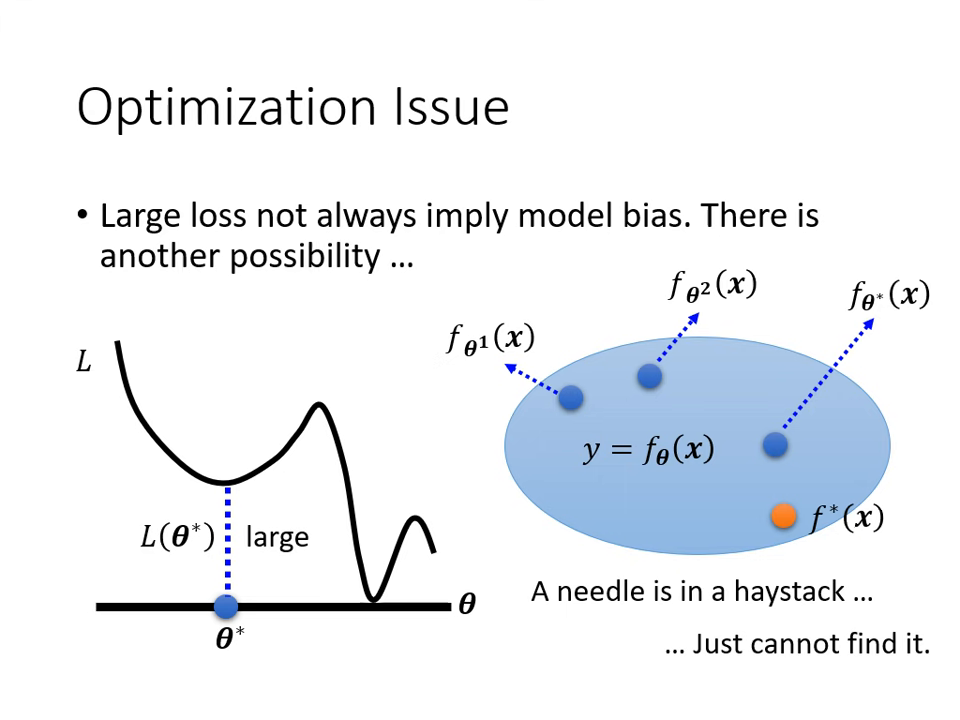
- 現象:函數集合夠大(針在海裡),但演算法(如 Gradient Descent)不給力,卡在局部最小值 (Local Minima),沒撈到針。
- 診斷方法:比較深淺模型。若 56 層網路的訓練損失比 20 層高,通常是最佳化問題,而非模型偏差(因為 56 層的彈性理論上一定大於 20 層)。
- 對策:更換最佳��化演算法或調整訓練策略。
- 原因 1:模型偏差 (Model Bias)
-
狀況 B:訓練損失小,但測試損失大 (Training Loss is small, Testing Loss is large)
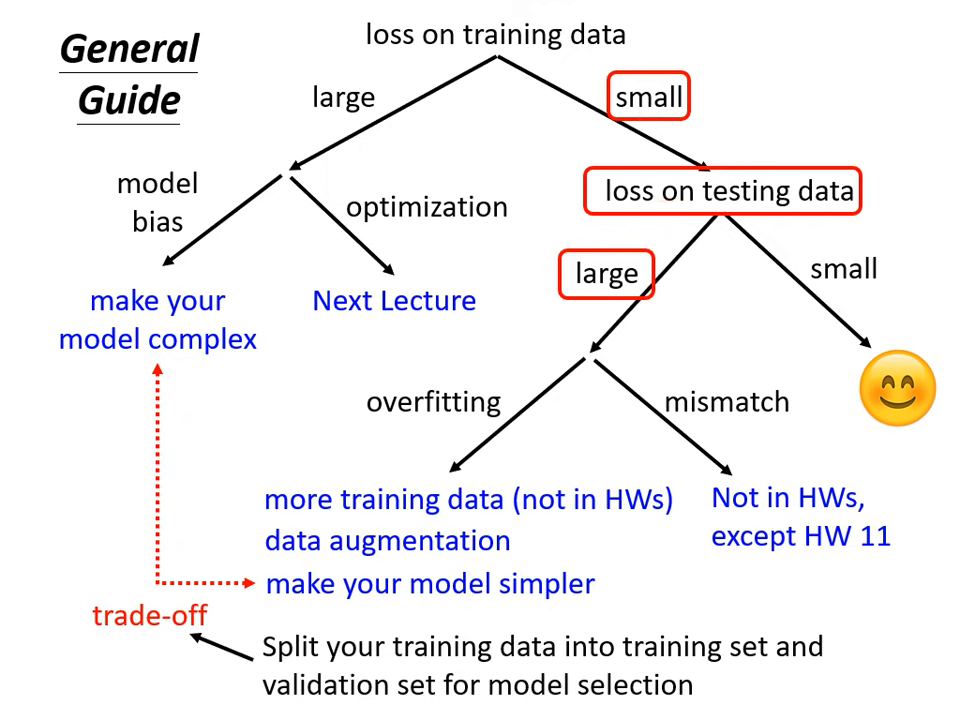
這可能是以下兩種情況之一:
-
狀況 B-1:過擬合 (Overfitting)
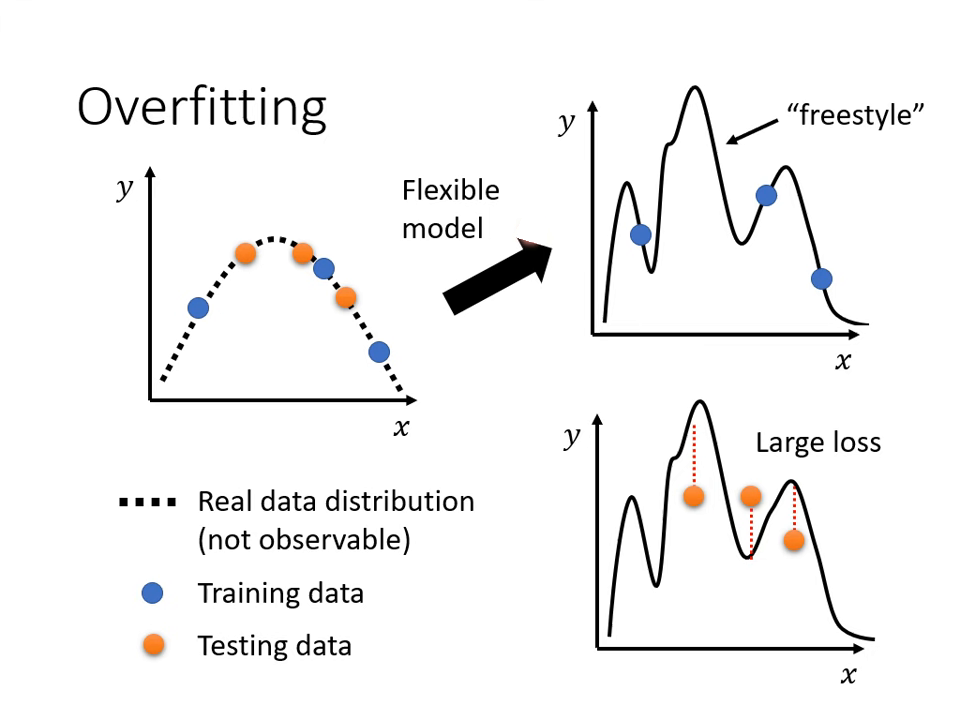
- 現象:模型彈性太大,產生了「Freestyle」,在訓練資料上完美擬合,但在沒看過的測試資料上表現極差(如極端例子:直接背下訓練集)。
- 對策:
- 增加訓練資料:最有效的方法。
- 資料增強 (Data Augmentation):
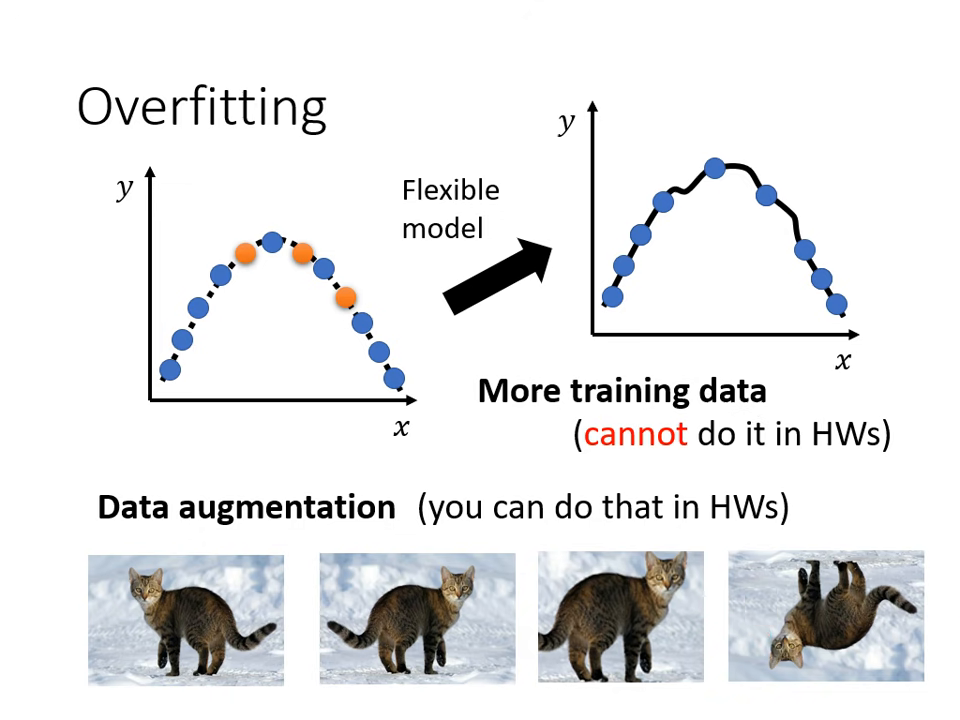 根據對問題的理解創造新資料(如圖片左右翻轉,但不可亂翻轉如上下顛倒)。
根據對問題的理解創造新資料(如圖片左右翻轉,但不可亂翻轉如上下顛倒)。 - 限制模型彈性:
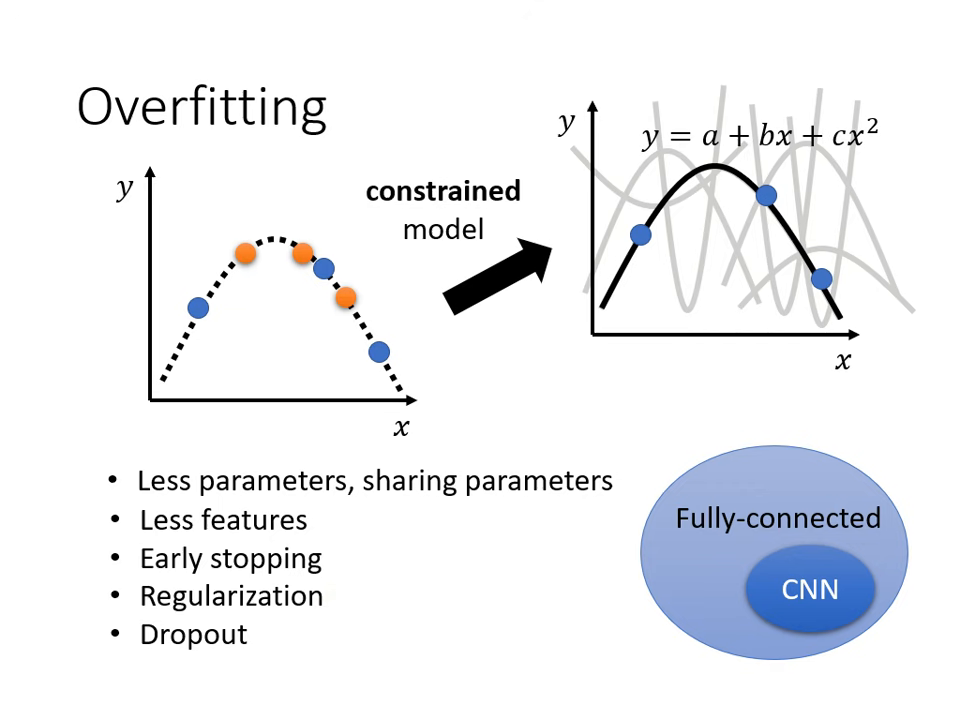 給予限制,使其接近真實分布。方法包括:減少參數、減少特徵、共用參數(如 CNN 結構)、早停法 (Early stopping)、正則化 (Regularization) 或 Dropout。
給予限制,使其接近真實分布。方法包括:減少參數、減少特徵、共用參數(如 CNN 結構)、早停法 (Early stopping)、正則化 (Regularization) 或 Dropout。
-
狀況 B-2:資料不匹配 (Mismatch)
- 現象:訓練資料與測試資料的分佈不同。此時增加訓練資料也無濟於事(如用 2020 年的數據預測 2021 年反常的點閱狀況)。
- 對策:需要對資料產生方式有深刻理解,並採用特定技術(如作業十一的設計)。
-
偏差與複雜度的權衡 (Bias-Complexity Trade-off)
1. 定義模型複雜度
- 參數越多、包含的函數集合 (Function Set) 越廣,模型就越複雜。
2. 複雜度對損失 (Loss) 的影響
- 訓練集 (Training):模型越複雜,訓練損失會持續下降。
- 測試集 (Testing):隨複雜度增加,測試損失會先下降;但超過臨界點後會因過擬合 (Overfitting) 而突然暴增。
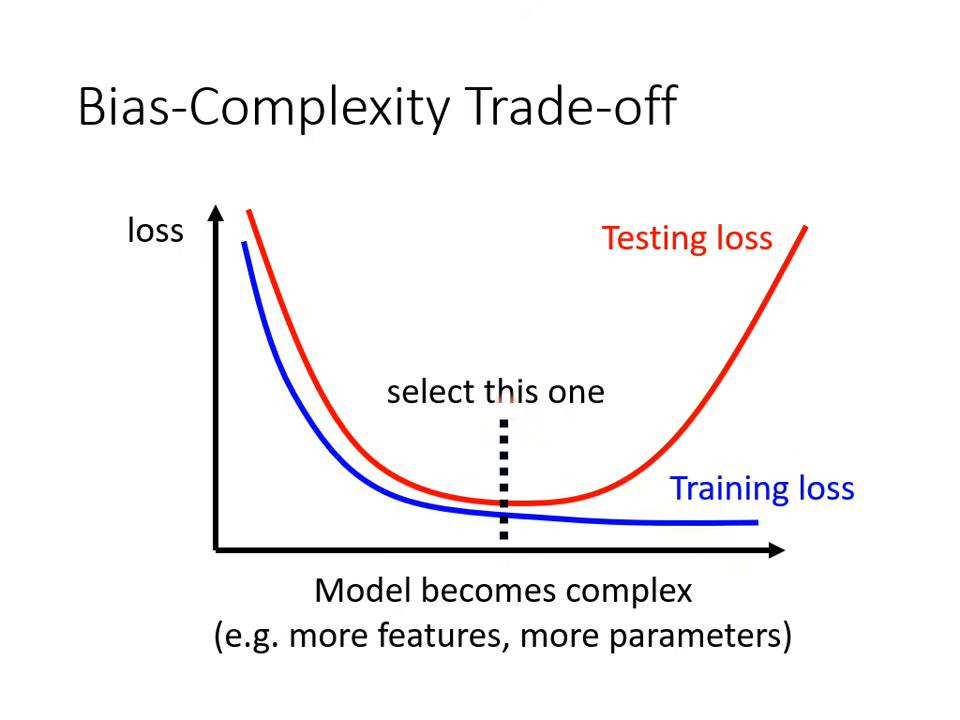
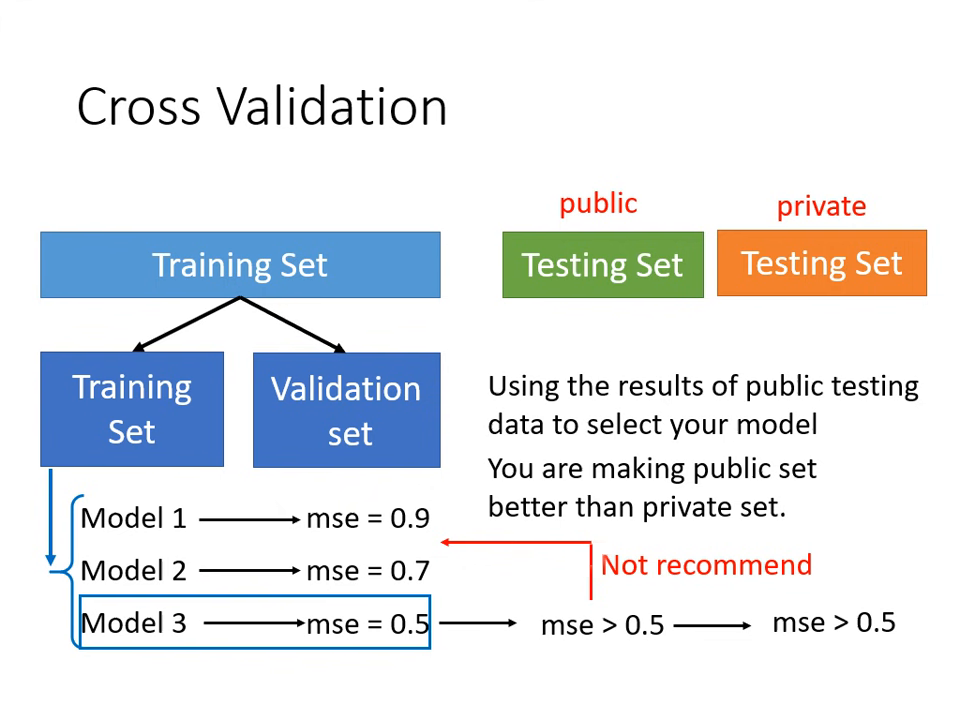
模型選擇與驗證策略 (Model Selection)
- 驗證集 (Validation Set):
- 將訓練資料切分為「訓練集」與「驗證集」(如 9:1 分)。
- 在訓練集訓練,並以驗證集的分數挑選模型。
- 挑選好後再上傳,這能讓公開分數較真實地反應私有分數。
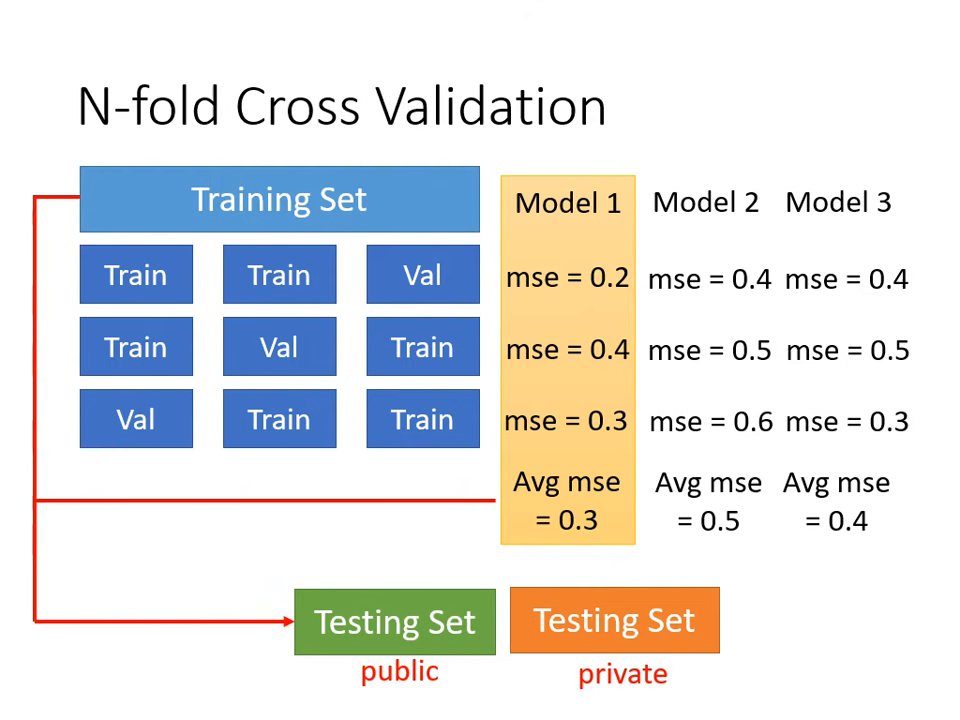
- N-折交叉驗證 (N-fold Cross Validation):
- 將訓練資料切成 N 等份,輪流以其中一份作驗證集,其餘為訓練集。
- 計算各模型在 N 種狀況下的平均表現,挑選最優模型,最後再用全部訓練資料重新訓練該模型。