卷積神經網路 (Convolutional Neural Network, CNN)
影像輸入設計:Flatten 方法的問題與反思
基本步驟
- 影像縮放 (Rescale):將圖片統一成固定大小(如 100 × 100)。
- 獨熱向量 (One-hot Vector):表示類別,維度長度決定可辨識的種類數量。
- 模型優化:通過 Softmax 後,追求預測值與正確標籤間的 Cross Entropy 最小化。
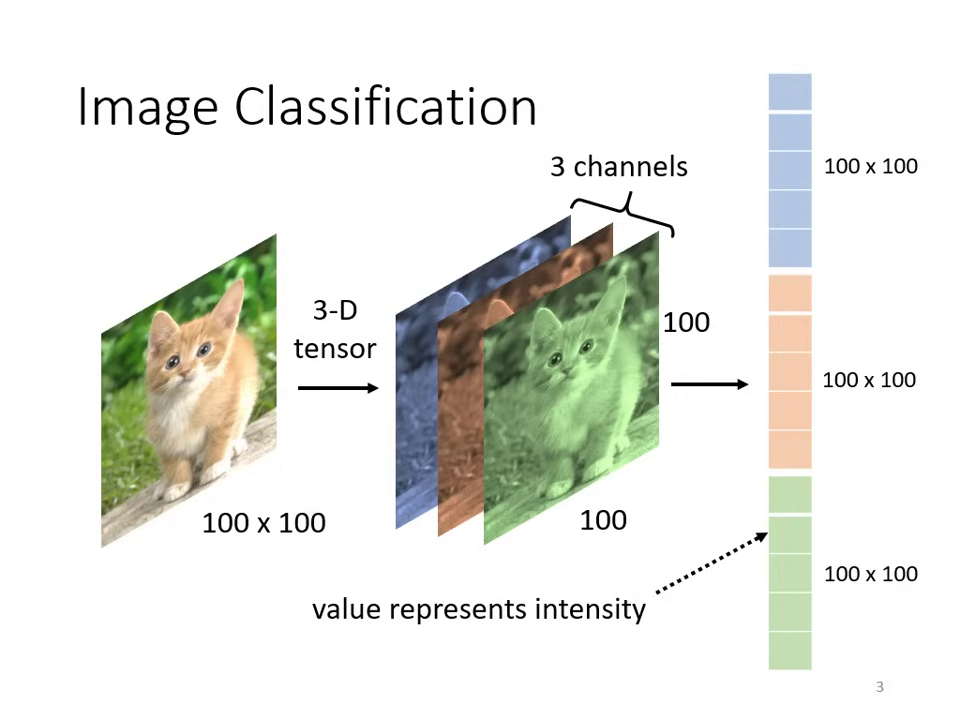
將圖片輸入到模型中
- 影像表示:彩色影像為三維張量 (Tensor),包含寬、高及 R G B 三個通道 (Channel)。
- 直覺思路:直接展平 (Flatten) 為向量輸入。
- 問題:參數量過大。如 100×100×3 輸入配 1000 個神經元,第一層即需 個權重,大幅增加 Overfitting 風險。
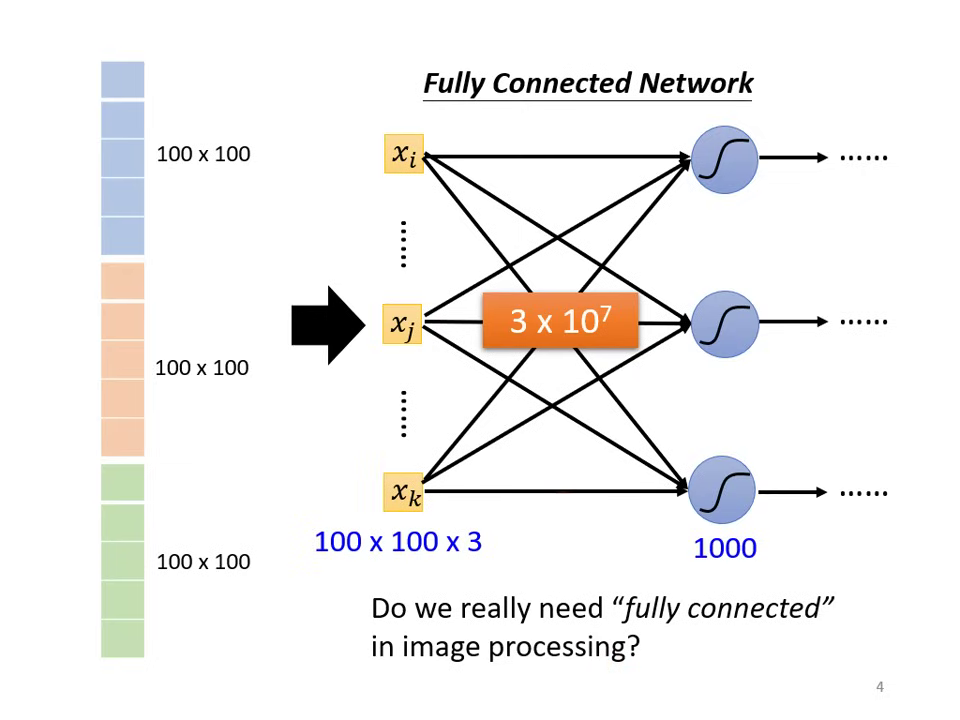
為什麼需要 CNN? (設計動機與影像特性)
在處理影像辨識時,若直接使用全連接網路 (Fully Connected Network),會面臨參數過多導致 Overfitting 的風險。CNN 透過對影像特性的三個關鍵觀察來簡化網路架構:
-
觀察一:偵測 Pattern 不需要看整張圖片
- 影像中的重要特徵(如鳥嘴、眼睛)通常只存在於局部區域。
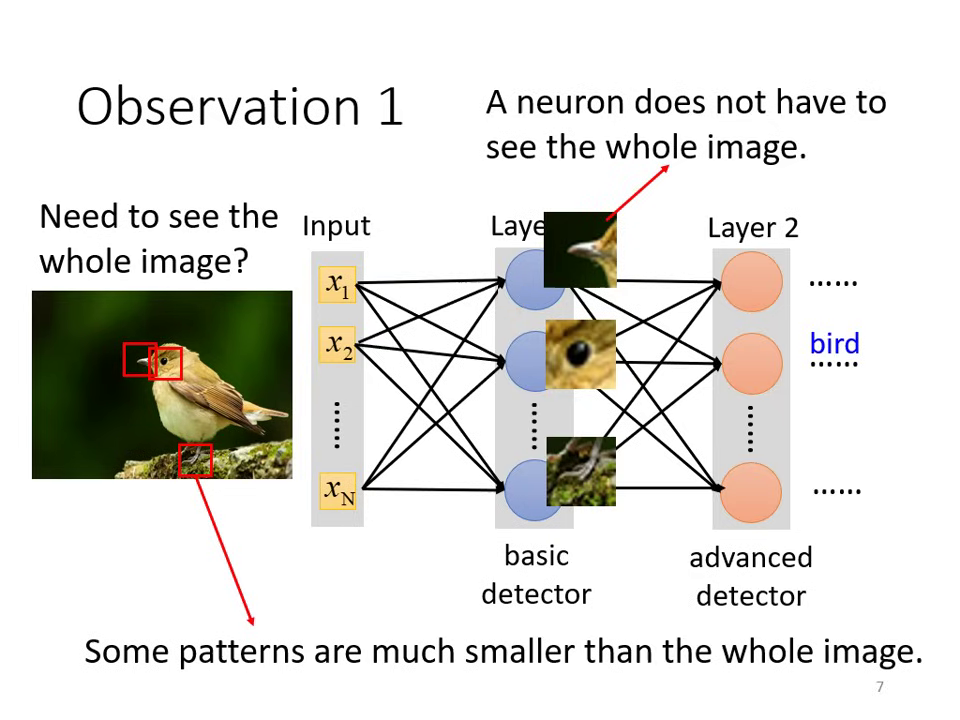
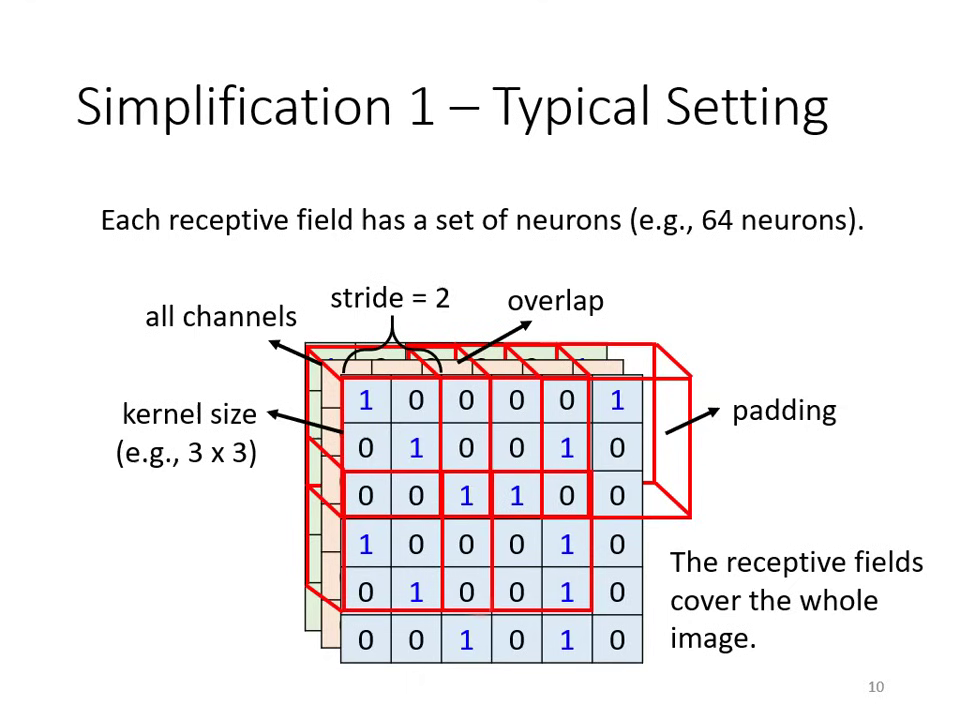
- 簡化方式: 引入 Receptive Field (感受野),每個神經元只負責守備一小塊區域。
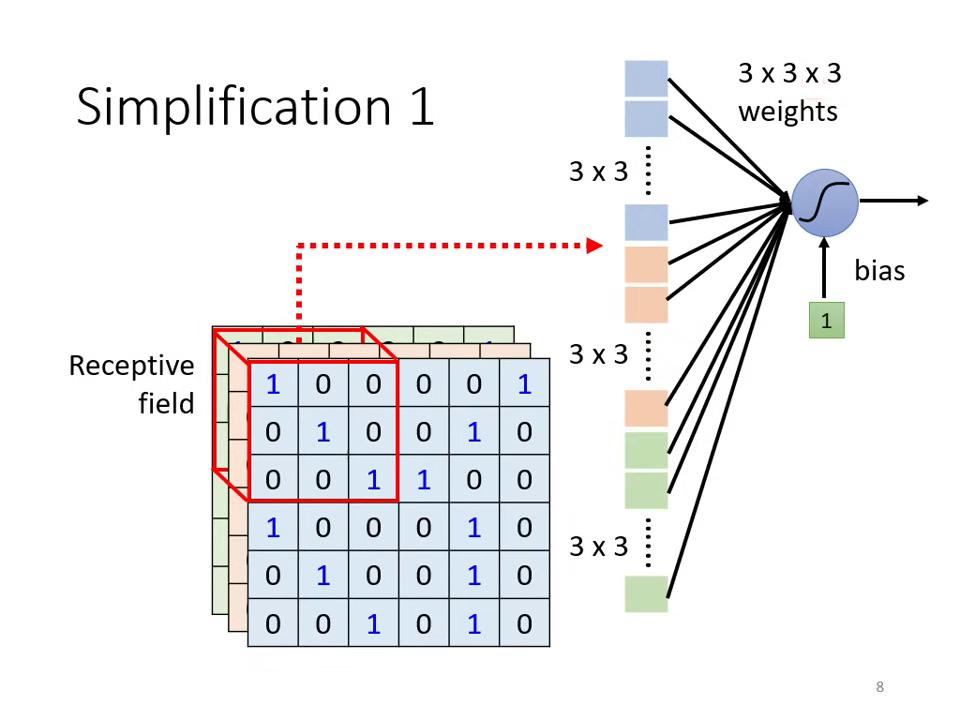
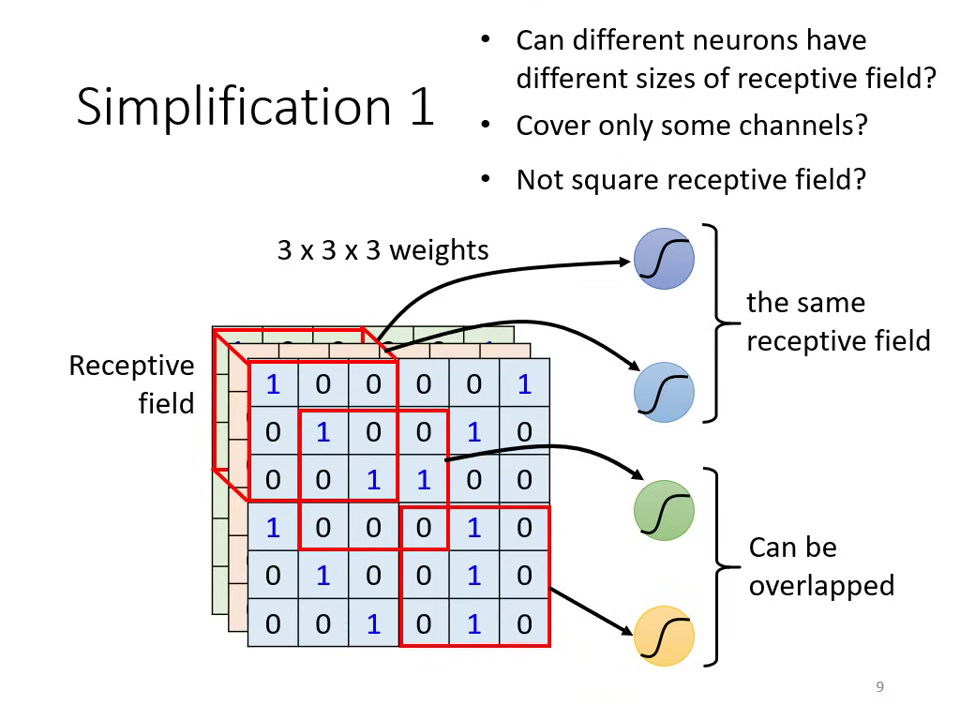
單一神經元的局部感受野計算 共享感受野的卷積特徵擷取
- 影像中的重要特徵(如鳥嘴、眼睛)通常只存在於局部區域。
-
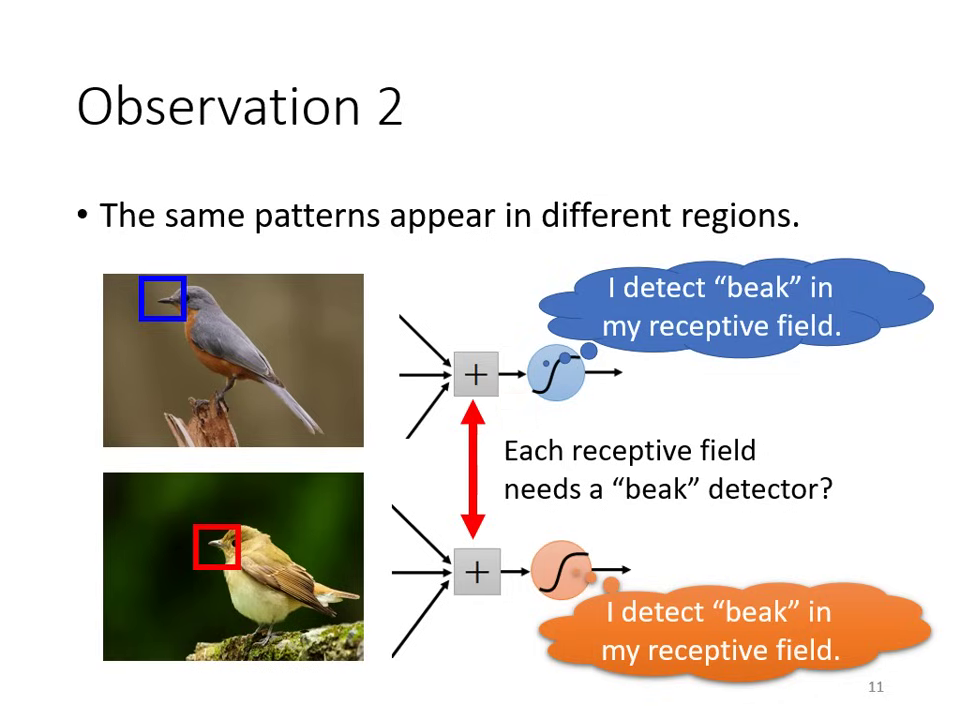
觀察二:同樣的 Pattern 會出現在不同位置
- 鳥嘴可能出現在左上角,也可能出現在中間。
- 簡化方式: Parameter Sharing (參數共享)。讓不同守備範圍的神經元共�用同一組參數(即 Filter)。
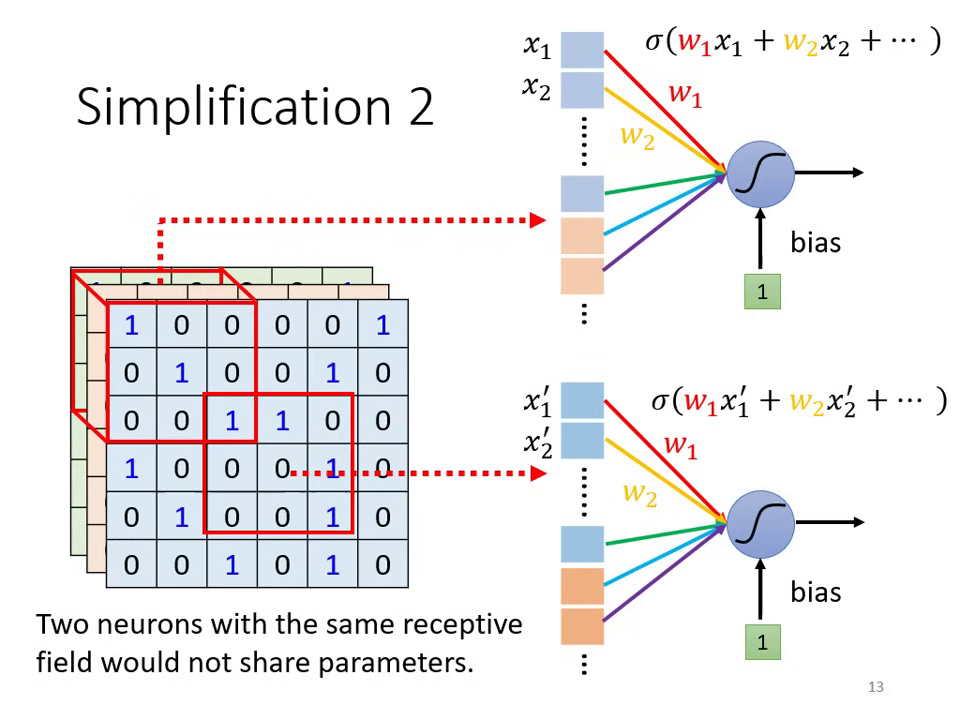
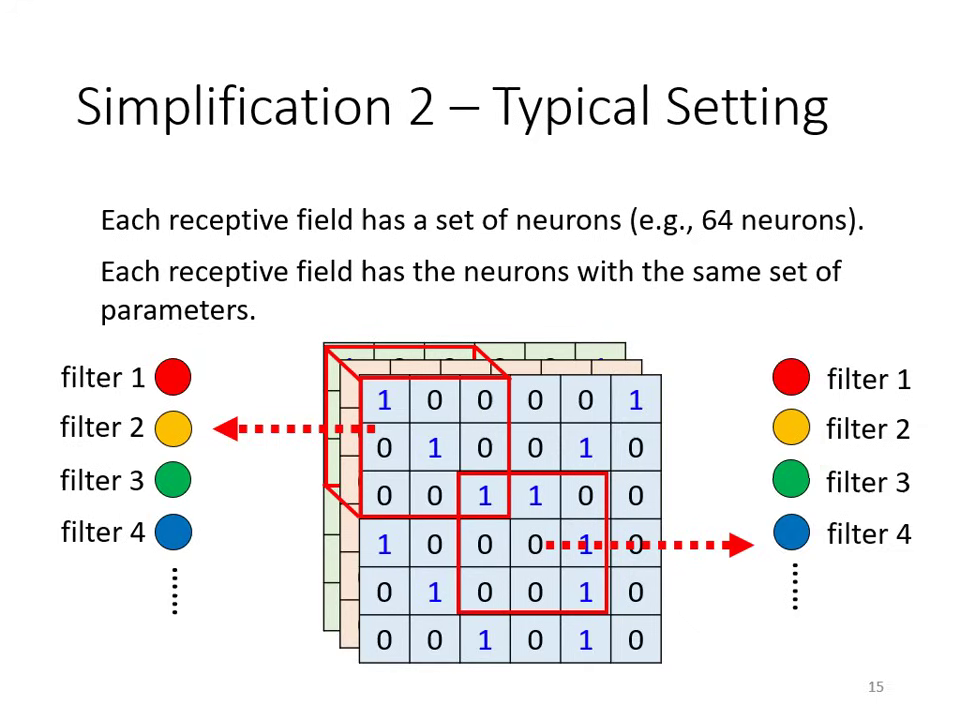
共享參數、不同感受野,產生不同輸出 不同感受野皆套用相同的 Filter(權重共享)
- 鳥嘴可能出現在左上角,也可能出現在中間。
-
觀察三:對影像做下採樣 (Subsampling) 不影響辨識
- 將圖片縮小後,人依然能辨認出物件。

- 簡化方式: Pooling (池化)。縮小圖片尺寸以減少運算量。
- 將圖片縮小後,人依然能辨認出物件。
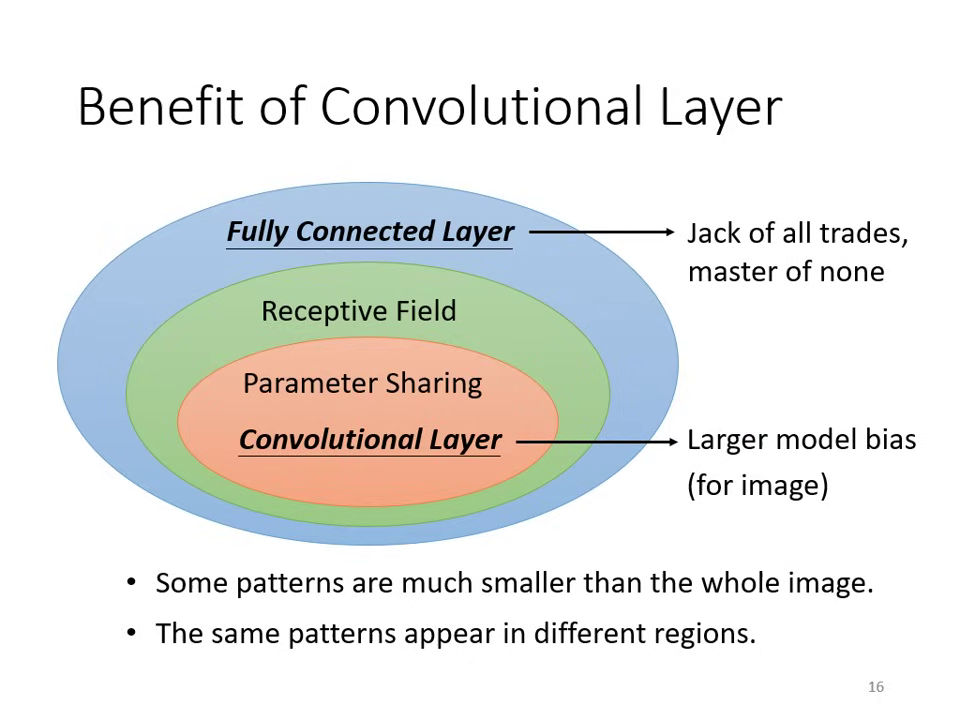
卷積層的優勢:受限的 Fully Connected Layer
卷積層 (Convolutional Layer) 本質上是 加上人為限制(Model Bias) 的 Fully Connected (FC) Layer,透過犧牲模型彈性來換取更好的訓練效率與抗過擬合能力。
核心觀察:從 FC 到 CNN 的限制
- 感受野 (Receptive Field):FC 原本能決定看整張圖片或局部範圍(將多餘權重設為 0),但 CNN 強制限制神經元只能守備特定範圍。
- 權值共享 (Parameter Sharing):FC 的神經元參數各自獨立,但 CNN 強制守備不同區域的同一組 Filter 必須共用參數。
效能分析:靈活性與偏置的平衡
- 全連接層 (FC):Model Bias 小、靈活性 (Flexibility) 極高。雖然能產生各類變化,但在特定任務(如影像辨識)上容易因參數量過大而導致 Overfitting,難以在特定任務上做好。
- 卷積層 (CNN):Model Bias 較大。雖然限制了模型的自由度,但它是專門為影像特性設計的(考慮局部性與平移不變性),因此在影像處理任務上表現更穩健且優異。
濾波器角度 (Filter Perspective) 介紹 CNN
卷積層基本定義
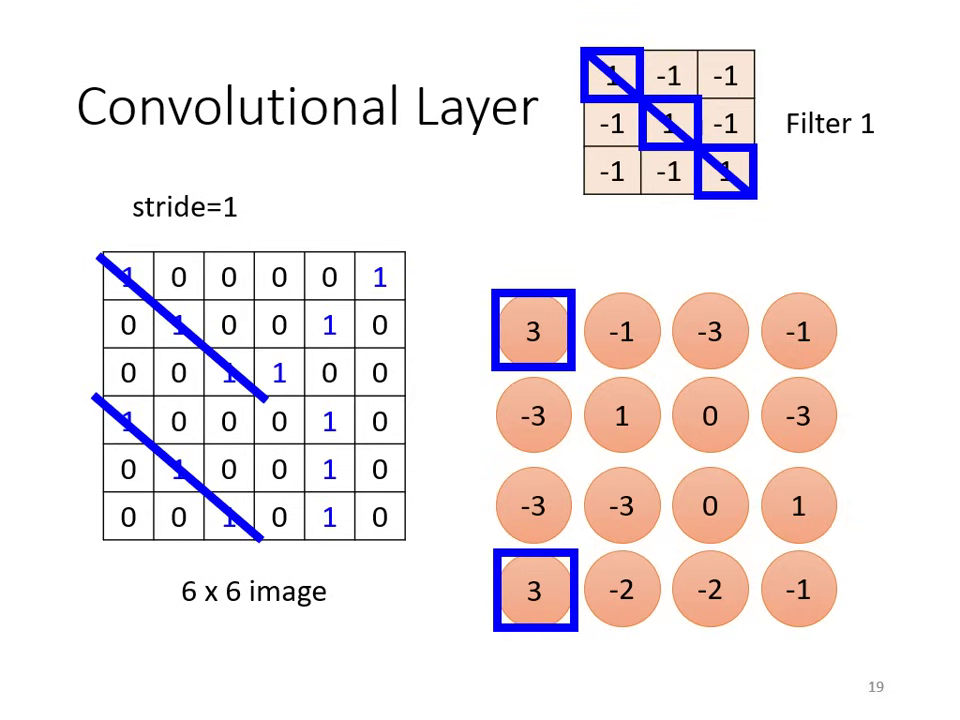
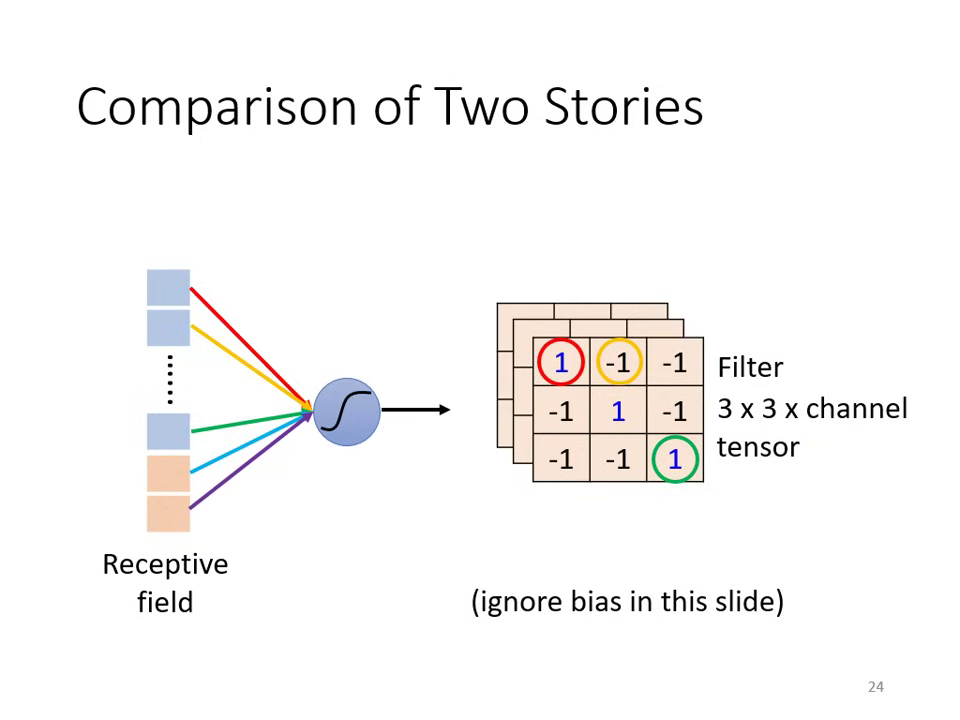
- 濾波器 (Filter) 的作用:卷積層包含多個 Filter,每個 Filter 都是一個三維張量(如 ),其任務是偵測影像中特定的 Pattern。
- 參數本質:Filter 內的數值即為模型待學習的 權值 (Weight),有時也包含偏置 (Bias)。
- 運算方式:內積 (Inner Product):Filter 與圖片對應區域的數值進行矩陣相乘後求和。當圖片出現與 Filter 相似的特徵時,內積數值最大。
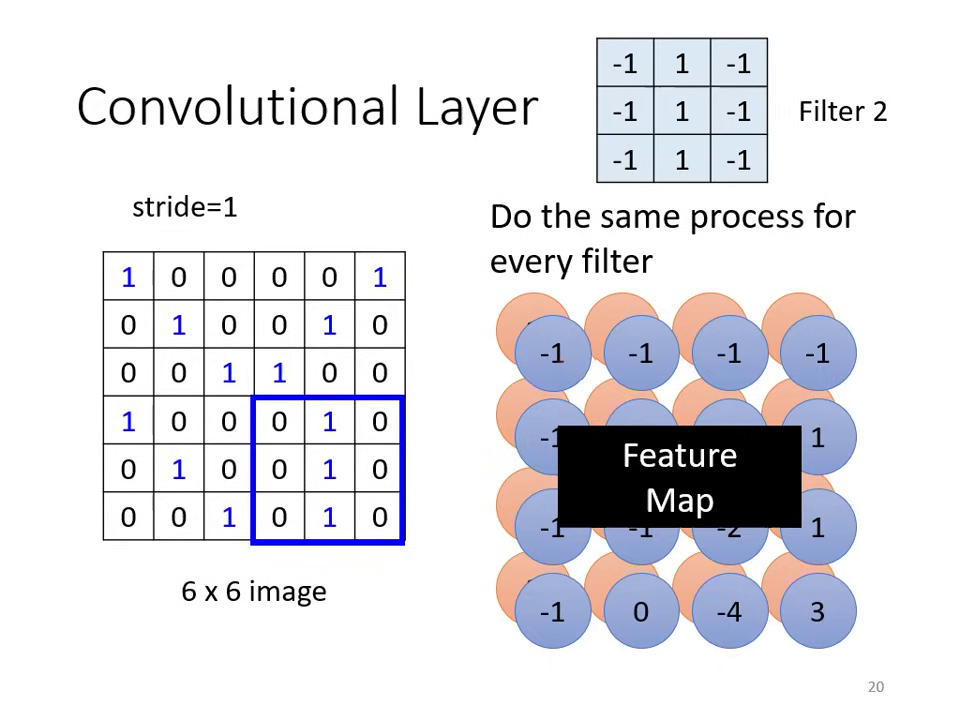
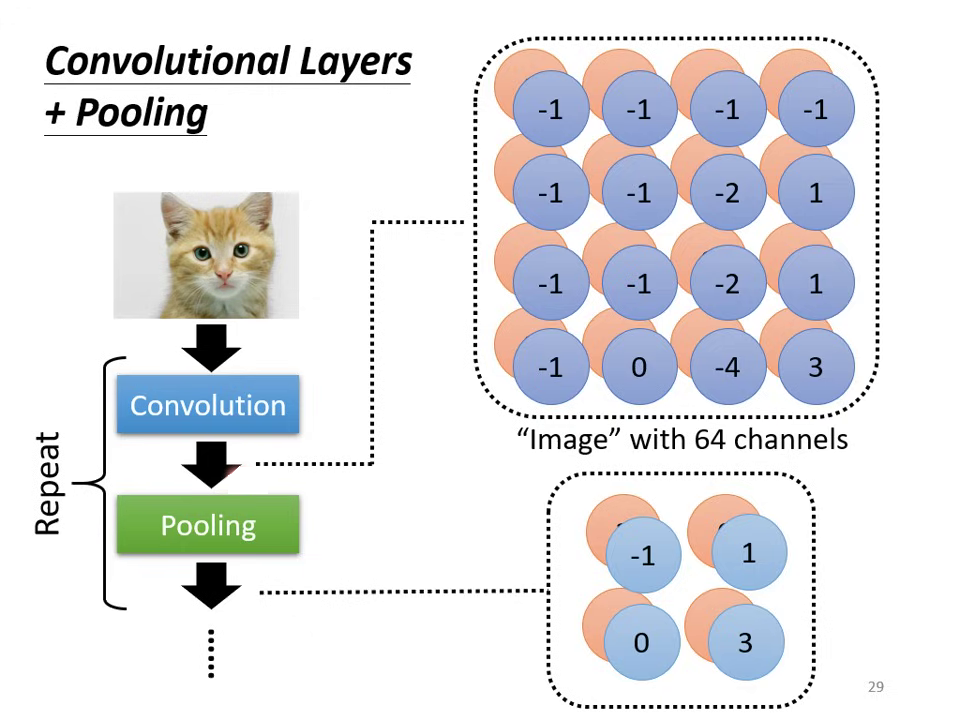
- 特徵圖 (Feature Map):每個 Filter 掃過整張圖片後會產生一組數值。若有 64 個 Filter,就會產生 64 個 Channel 的新圖片,稱為 Feature Map。
 |  |
|---|---|
| Filter 透過內積運算偵測影像特定 Pattern | 多個 Filter 各自產生特徵圖,構成多通道 Feature Map |
多層卷積機制
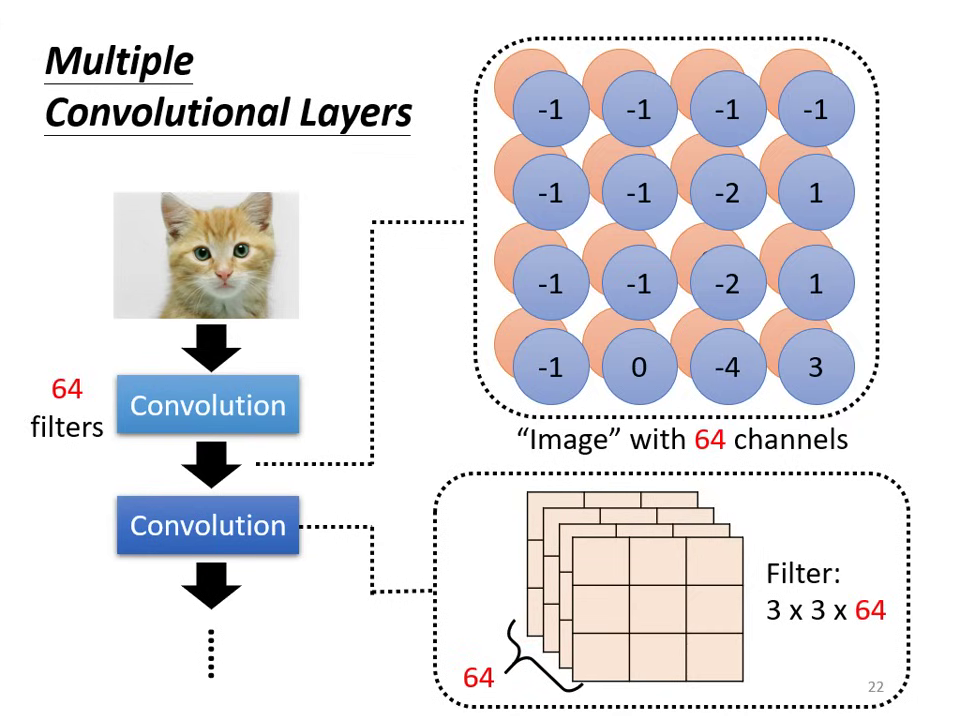
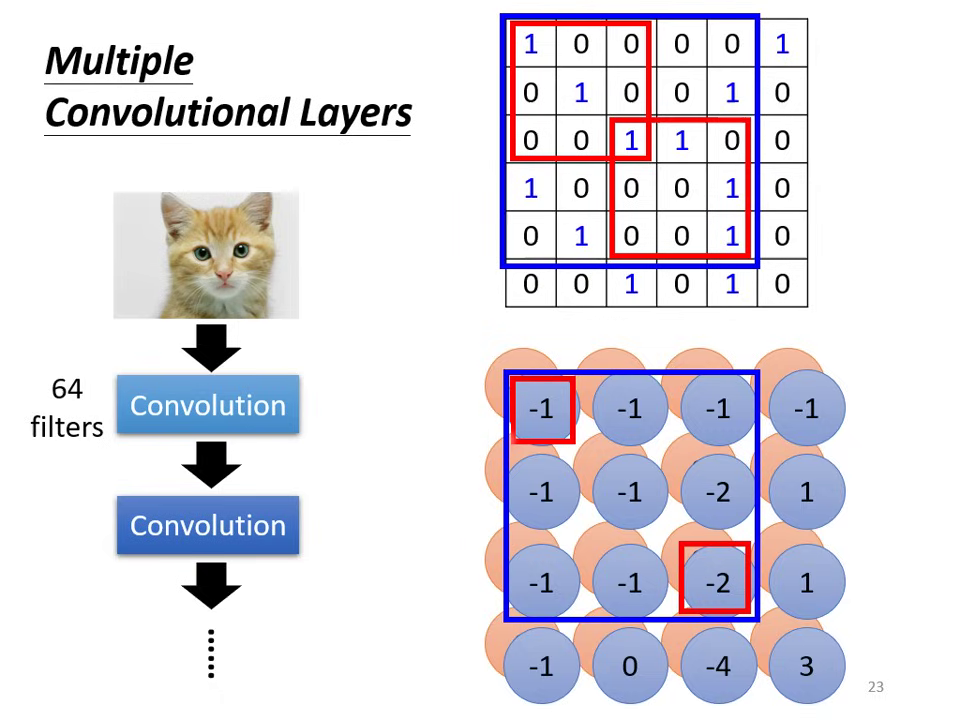
- 深度匹配:第二層卷積的 Filter 高度(深度)必須等於第一層輸出的 Channel 數(例如前層輸出 64 個 Channel,後層 Filter 的深度即為 64)。
- 視野演進 (Receptive Field Evolution):即使 Filter 大小固定(如 ),隨著網路疊深,��深層神經元在原圖上考慮的範圍會越來越大(如第二層的 實際上對應原圖的 ),因此深層網路能偵測更大尺寸的 Pattern。
 |  |
|---|---|
| 後層 Filter 深度需對齊前層 Channel 數 | 卷積層加深使感受野逐步擴大 |
神經元角度 (Neuron) vs. 濾波器角度 (Filter)
這兩種觀點在數學上是一模一樣的,只是從不同視角來說明 CNN 的機制。
| 影像特性與觀察 | 神經元角度 (Neuron) | 濾波器角度 (Filter) |
|---|---|---|
| 觀察一:局部性 (不需看整張圖) | 神經元只守備特定的 感受野 (Receptive Field) | 使用 Filter 偵測局部範圍內的 Pattern |
| 觀察二:平移不變性 (Pattern 會出現在不同位置) | 守備不同區域的神經元可以 共用參數 (Shared Weights) | 同一個 Filter 掃過 (Slide) 整張圖片進行運算(即卷積操作) |
核心結論: 所謂的 「參數共享」,本質上就是將一組 「Filter」 掃過整張影像。這種設計賦予了 CNN 強大的 Model Bias,使其在影像任務上比全連接層更有效率且不易過擬合。
CNN 的核心結構
卷積層 (Convolutional Layer)
卷積層是 Receptive Field 與 Parameter Sharing 的結合,其 Model Bias 較大(針對影像設計),但能有效避免 Overfitting。
- 濾波器 (Filter): 每個 Filter 是一個三維 Tensor(長 × 寬 × 通道數),負責偵測特定的 Pattern。
- 步長 (Stride): Filter 每次移動的距離。
- 填充 (Padding): 若 Filter 超出影像邊界,則補零 (Zero Padding) 或補平均值以維持尺寸。
- 特徵圖 (Feature Map): Filter 掃過整張圖片後的輸出結果。若有 64 個 Filter,就會產生 64 個通道的新圖片。
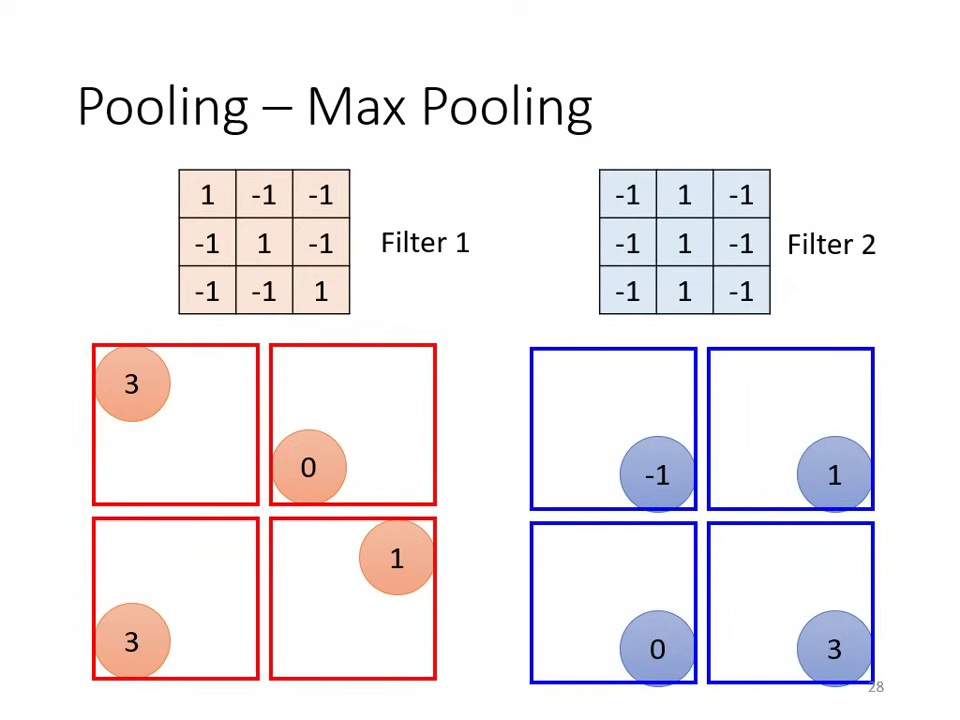
池化層 (Pooling)
- 功能: 負責把圖片變小,減少運算量。
- 常見方式: Max Pooling (在一組數字中選最大的作為代表) 或 Mean Pooling。
- 趨勢: 隨著運算能力增強,現代有些網路會捨棄 Pooling,改用全卷積架構。
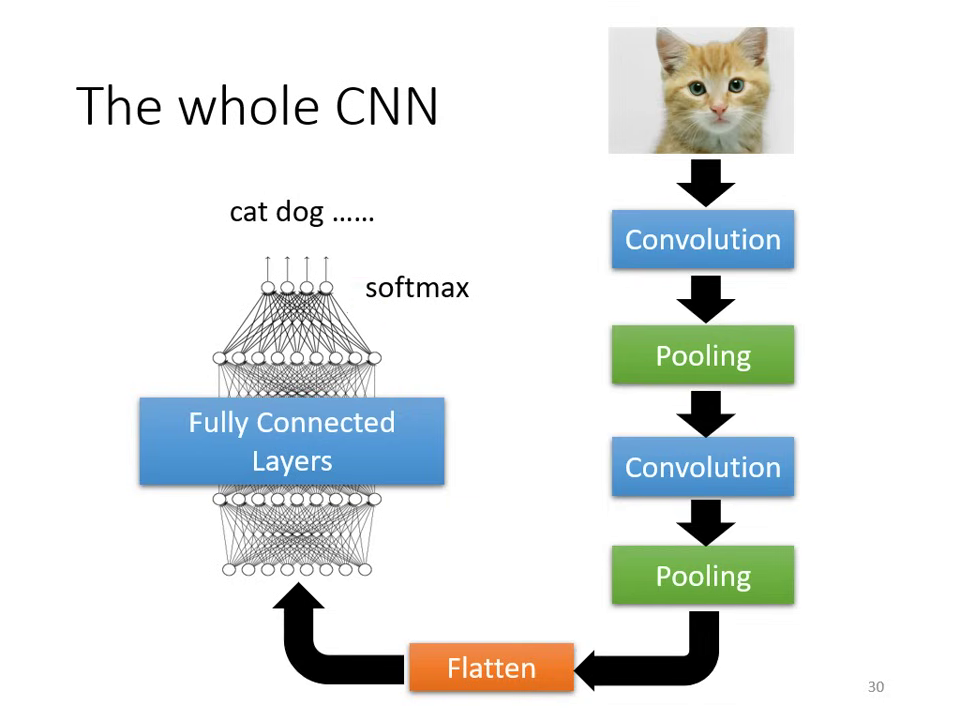
扁平化與全連接層 (Flatten & Fully Connected Layer)
- 在經歷多次卷積與池化後,將多維向量 Flatten (拉直) 變成一維向量。
- 最後丟入 Fully Connected Layer 並搭配 Softmax 進行分類輸出。
 |  |
|---|---|
| 卷積與池化逐層抽取影像特徵 | 特徵學習後進行分類的 CNN 流程 |
案例研究:AlphaGo
雖然下圍棋不是影像辨識,但棋盤具備與影像相似的特性:
- 局部性: 棋盤上的重要 Pattern(如叫吃)看 5×5 範圍即可辨認。
- 平移不變性: 同樣的局勢可以出現在棋盤任何位置。
- 關鍵差異: AlphaGo 的設計中沒有使用 Pooling,因為棋盤上隨意移除行列會導致資訊嚴重受損。

CNN 的限制與挑戰
- 缺乏空間變換不變性: CNN 無法自動處理影像的放大縮小 (Scaling) 或 旋轉 (Rotation)。
- 解決方案:
- 資料增強 (Data Augmentation): 訓練時將圖片截取、放大或旋轉。
- Spatial Transformer Layer: 另一種專門處理此問題的網路架構。